χ0: A Live-Stream Robotic Teamwork for Clothing Manipulation from Zero to Hero
Published
December 24, 2025
Report
2602.09021
Repository
OpenDriveLab/kai0
[email protected]
By
HKU MMLab
Community
Discord
Veni, vidi, vici.
We will release data, checkpoints, and host Challenge in 2026.
Three tasks varying from folding to hanging, each covering a 4-hour duration, presented in 100x time-lapse format with critical segments highlighted at 2-5x speed.
Mode Consistency System Architecture-Left: Human expert demonstration collection. Middle: Mixing models from different data sources via Model Arithmetic. Right: Real-robot inference. Bottom: DAgger Feedback and Stage Advantage from on-policy experience.

Distribution dynamics of Ptrain, Qmodel, and Ptest.
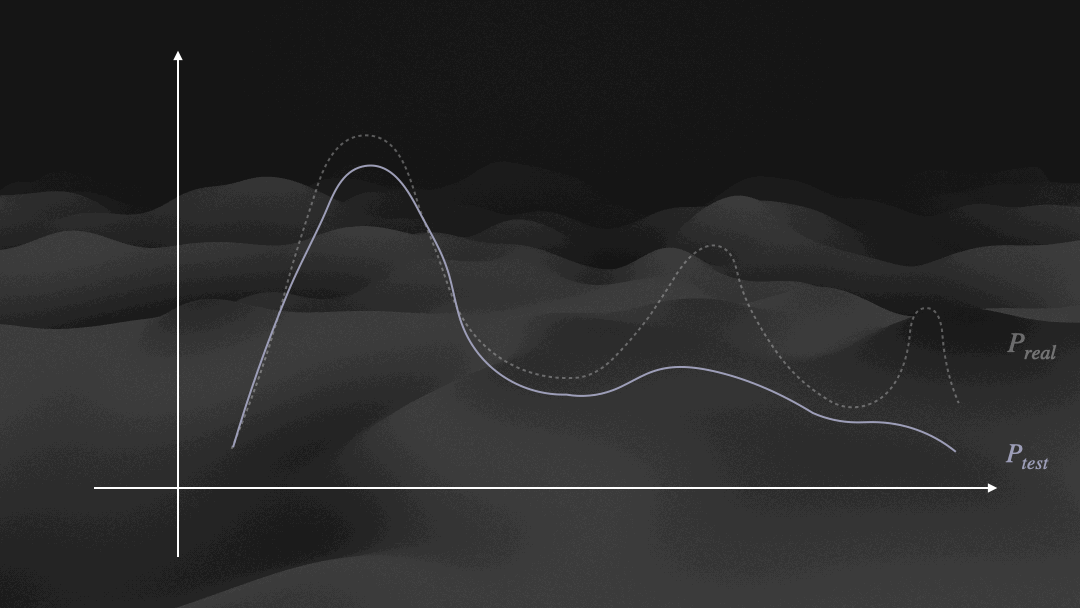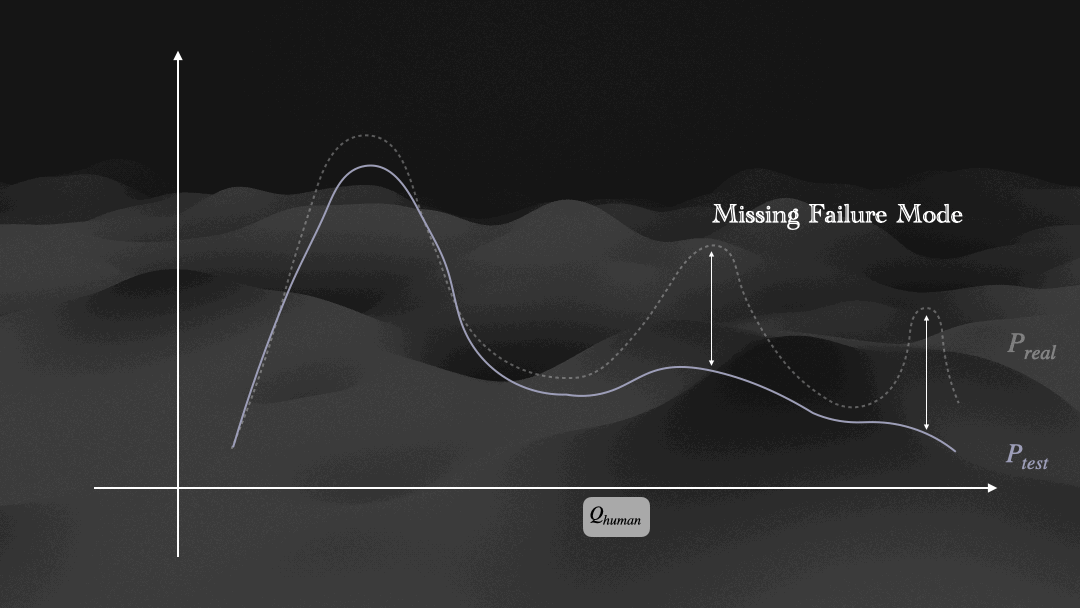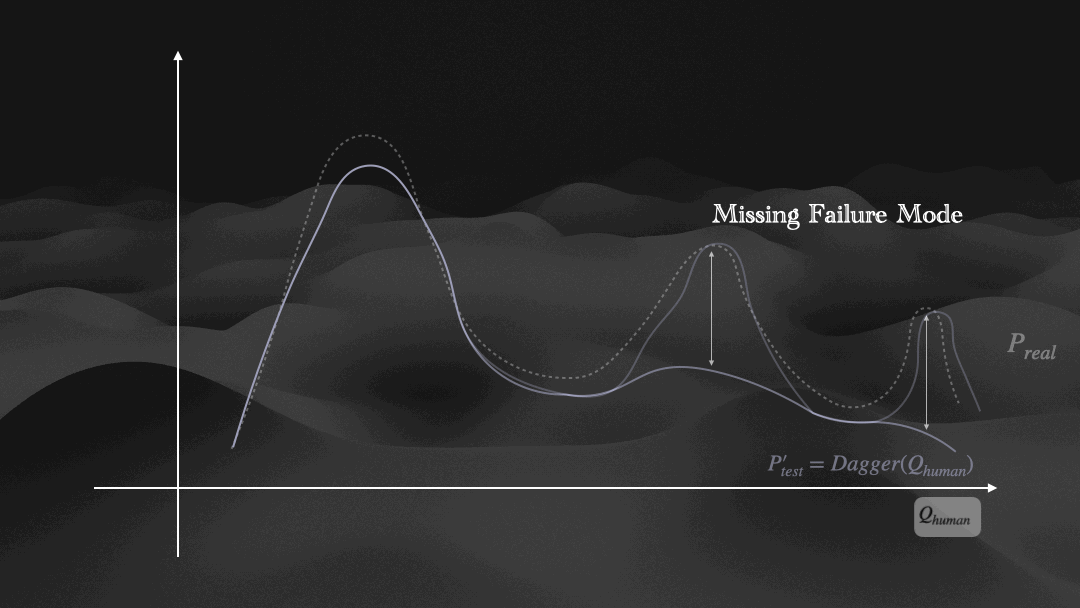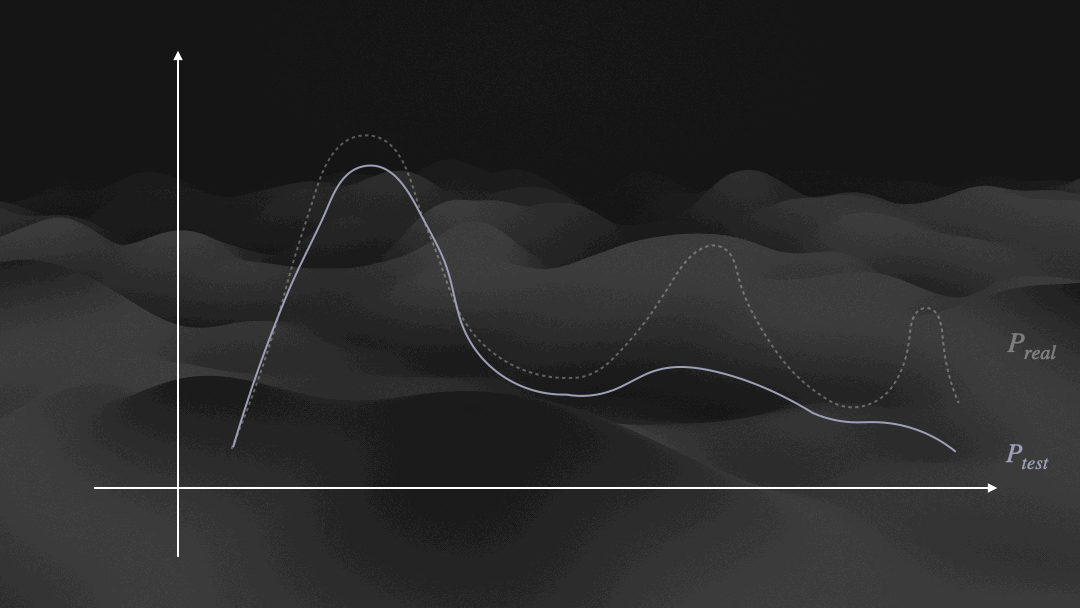
DAgger-Injecting on-policy recovery trajectories to expand Ptrain towards underrepresented failure modes in Preal.

Inference Optimization-Minimizing execution jitter to ensure smooth translation from Qmodel to Ptest.
Interactive 3D t-SNE visualization of action distributions for Ptrain, Qmodel, and Ptest.Click and drag to rotate the plot.
Improved data collection methods and on-policy recovery trajectories effectively enhance the model's error recovery capability, significantly increasing success rate and reducing recover cost (fewer retry attempts per failure). X-axis: baseline, improved baseline, + heuristic DAgger, + DAgger.
Spatio-temporal augmentation substantially enhances model performance, increasing success rate and throughput (more task completions per unit time). X-axis: baseline, +spatio-temp. augment.
Inference optimization through chunk-wise temporal smoothing and real-time chunking ensures the policy's intended actions are translated flawlessly into smooth, coherent real-robot execution, improving throughput (more task completions per unit time). X-axis: sync, + inchunk smooth, + temp smooth, + RTC.

We merge models trained on different data subsets into a single entity using weight interpolation, with the mixing weights optimized against on-policy data.
The merged model surpasses both the best constituent models and the oracle model trained on the full dataset across multiple tasks, evidencing that Model Arithmetic successfully assimilates the distinct policy manifolds learned from diverse data subsets.
Comparison of cumulative progress induced by different methods along an inference-time manipulation trajectory. Green and red segments indicate higher- and lower-ranked actions based on predicted advantage, reflecting relative preference for task advancement. Direct+Stage (ours) produces smoother and more consistent progress accumulation than Value-diff.
Value-diff computes the advantage by subtracting two independently predicted state values. Direct predicts the advantage as the relative improvement from paired observations. Direct+Stage (ours) uses stage-conditioned direct advantage prediction for long-horizon training, achieving smoother results (lower MSTD), greater stability (higher SFR), and higher success rates.
@article{hkummlab2025kai0,
title = {A Live-Stream Robotic Teamwork for Clothing Manipulation from Zero to Hero},
author = {HKU MMLab},
journal = {HKU MMLab Research Blog},
year = {2025},
note = {https://mmlab.hk/research/kai0},
}Stay in the loop
Get notified about live demos, challenges, and the latest research updates.
No spam, ever. Unsubscribe anytime.