
Research

- Fully Open-sourcewith CAD, Assembly Guide, Electronics, and Software.
- ~$1,400 Material Cost.
- 21 Fully Actuated DoF.
"Veni, Vidi, Vici" - I came, I saw, I conquered. We aim to conquer the "Mount Everest" of robotics: 100% reliability in real-world garment manipulation. We demonstrate how to take a system from 0% to 100% reliability using a fraction of the standard cost—specifically, within 20 hours of human demonstration and 8xA100 GPUs, rather than the tens of thousands of hours and hundreds of GPUs typically required.
- Mode Consistency: We argue that not all data is equally valuable.
- Model Arithmetic: We move beyond the search for a single perfect checkpoint.
- Stage Advantage: To conquer the "last mile", we decompose tasks into semantic stages.

CelebFaces Attributes Dataset (CelebA) is a large-scale face attributes dataset with more than 200K celebrity images, each with 40 attribute annotations. The images in this dataset cover large pose variations and background clutter. CelebA has large diversities, large quantities, and rich annotations, including
- 10,177 number of identities,
- 202,599 number of face images, and
- 5 landmark locations, 40 binary attributes annotations per image.
The dataset can be employed as the training and test sets for the following computer vision tasks: face attribute recognition, face recognition, face detection, landmark (or facial part) localization, and face editing & synthesis.

T2I-CompBench and T2I-CompBench++ are the first comprehensive benchmark for compositional text-to-image generation. It uniquely incorporates both template-based and natural language formats, and covers seen and unseen compositions, as well as scenarios with multiple and mixed objects and attributes. The prompts in this benchmark offer significant diversity, including:
- 8,000 prompts of compositionality, featuring 2,470 nouns, 33 colors, 32 shapes, 23 textures, 10 spatial relationships, and 875 non-spatial relationships.
- 4 categories and 8 sub-categories, addressing attribute binding, numeracy, object relationships, and complex compositions.
- 4 types of evalution metrics, specifically designed for accuracy assessment.
The benchmark can be used as both training and test sets to evaluate multiple text-to-image generation capabilities: compositional text-to-image generation, prompt following ability, and the generation of images from complex prompts.
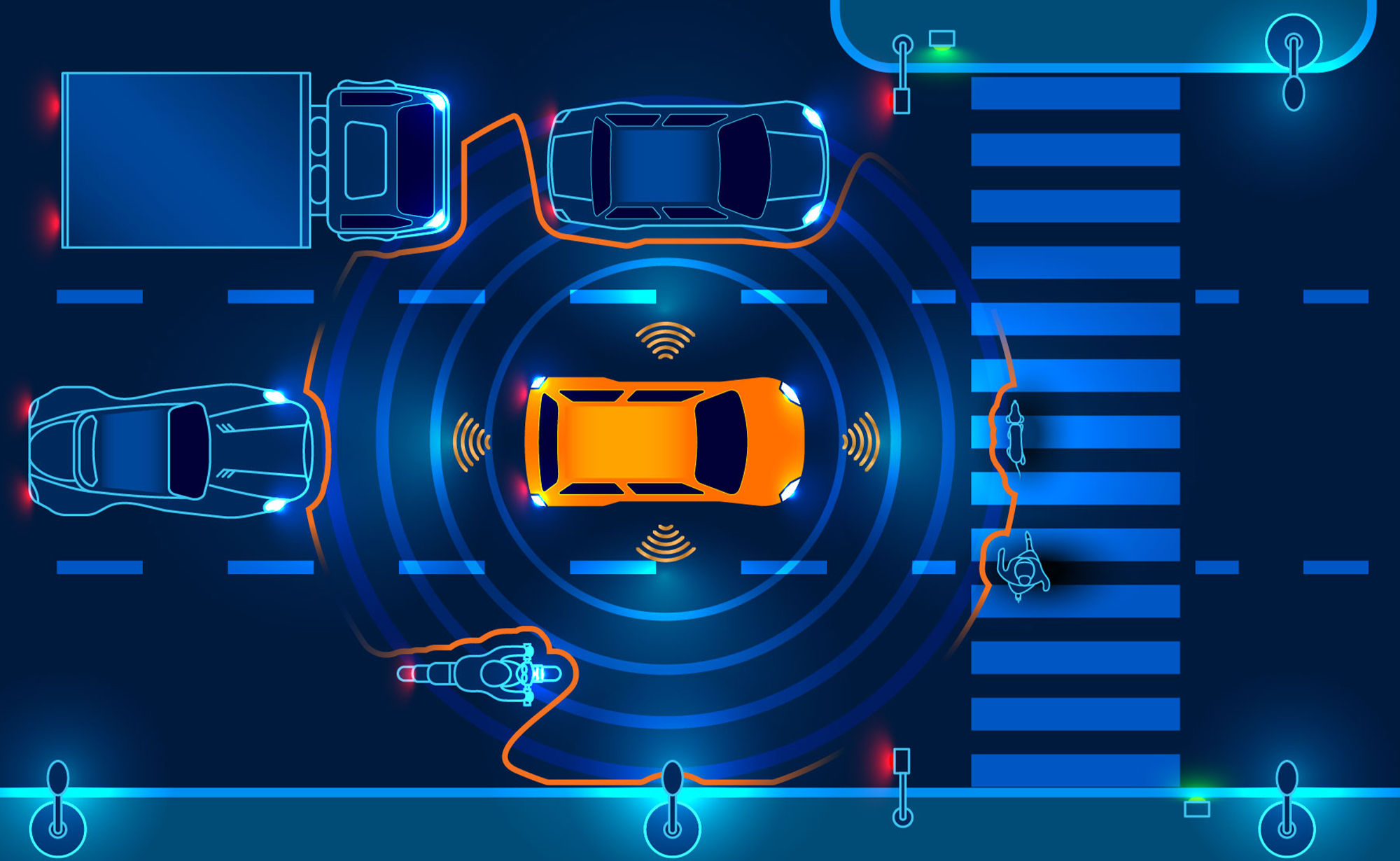
🚘 Planning-oriented philosophy: UniAD is a Unified Autonomous Driving algorithm framework following a planning-oriented philosophy. Instead of standalone modular design and multi-task learning, we cast a series of tasks, including perception, prediction and planning tasks hierarchically.
🏆 SOTA performance: All tasks within UniAD achieve SOTA performance, especially prediction and planning (motion: 0.71m minADE, occ: 63.4% IoU, planning: 0.31% avg.Col)

AnimateDiff is an innovative AI model that extends text-to-image generation to create animated videos. It achieves this by integrating a motion module, trained on vast amounts of video data to understand realistic movement. This allows users to generate dynamic animation sequences directly from text prompts. Key features include:
- Transforming static images into dynamic video.
- Diverse animation styles, from anime to photorealistic.
- Precise camera motion control (pan, zoom, rotate) using LoRA.
- Compatibility with existing models like Stable Diffusion and ControlNet.
AnimateDiff significantly lowers the barrier to animation creation, enabling more creators to bring their textual ideas to life.
Explore All Works







Discover All
Projects and Datasets
Projects and Datasets
