Projects & Datasets
Project
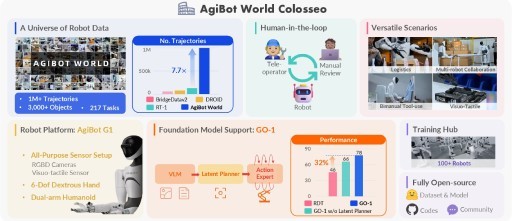
AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
AgiBot World Colosseo is a full-stack and open-source embodied intelligence ecosystem. Based on our hardware platform AgiBot G1, we construct AgiBot World—an open-source robot manipulation dataset collected by more than 100 homogeneous robots, providing high-quality data for challenging tasks spanning a wide spectrum of real-life scenarios.
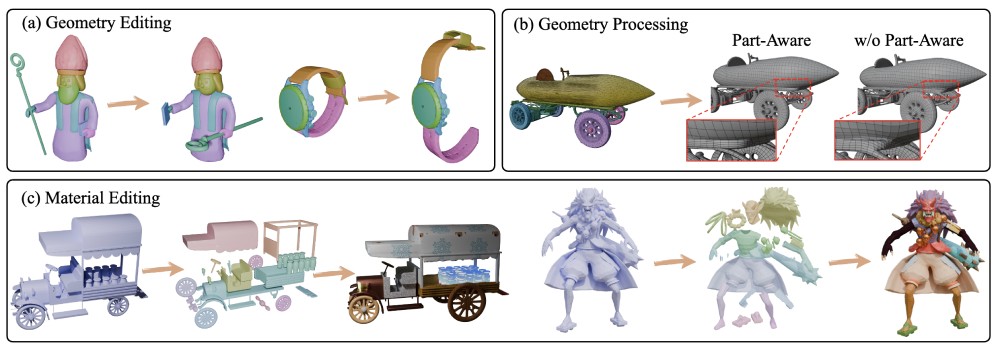
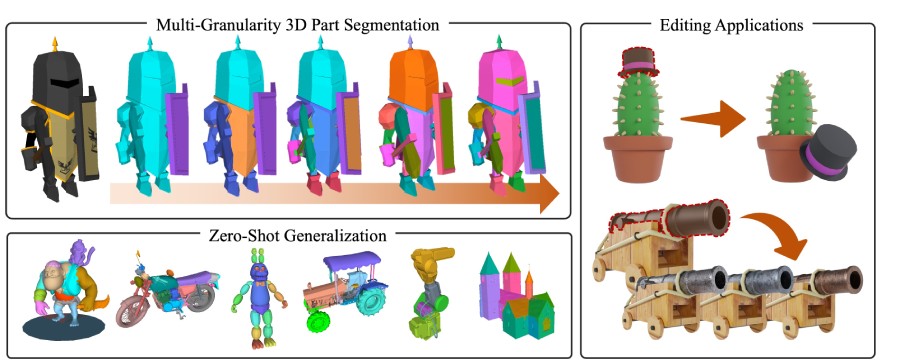
HoloPart: Generative 3D Part Amodal Segmentation
HoloPart is a novel diffusion-based model that completes partial 3D part segments into full, semantically meaningful parts, even when occluded. It combines local attention for fine-grained geometry and global context attention for shape consistency.


UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
UniVLA is a unified vision-language-action framework that enables policy learning across different environments. By deriving task-centric latent actions in an unsupervised manner, UniVLA can leverage data from arbitrary embodiments and perspectives without action labels. After large-scale pretraining from videos, UniVLA develops a cross-embodiment generalist policy that can be readily deployed across various robots by learning an action decoding with minimal cost.

Cross-Embodiment

AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
AnimateDiff enables animation generation from personalized text-to-image diffusion models by training plug-and-play motion modules. These modules learn transferable motion priors and use MotionLoRA for efficient adaptation without tuning the base models.






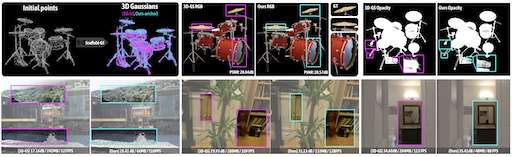
Scaffold-GS: Structured 3D Gaussians for View-Adaptive Rendering
Scaffold-GS organizes sparse 3D Gaussians around structured anchors in space, dynamically predicting rendering attributes based on viewpoint and distance. It improves rendering quality and efficiency through structured anchor growth and pruning strategies.





T2I-CompBench: A Comprehensive Benchmark for Open-world Compositional Text-to-image Generation
T2I-CompBench is a comprehensive benchmark with 6,000 compositional prompts across attribute binding, object relationships, and complex compositions. It includes novel evaluation metrics and GORS, a fine-tuning approach to enhance compositional generation capabilities.

UniAD: Planning-oriented Autonomous Driving
UniAD is a Unified Autonomous Driving algorithm framework following a planning-oriented philosophy. Instead of standalone modular design and multi-task learning, we cast a series of tasks, including perception, prediction and planning tasks hierarchically.

End-to-End
Autonomous Driving
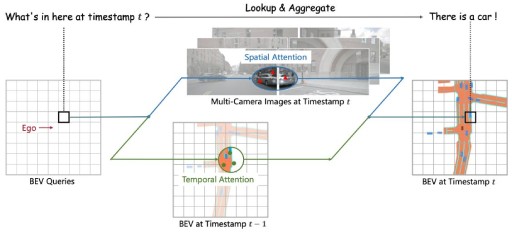
BEVFormer: Learning Bird's-Eye-View Representation From LiDAR-Camera via Spatiotemporal Transformers
A paradigm for autonomous driving that applies both Transformer and Temporal structure to generate BEV features.

Bird's-Eye-View

BungeeNeRF: Progressive Neural Radiance Field for Extreme Multi-Scale Scene Rendering
BungeeNeRF introduces a progressive training scheme that incrementally refines NeRF representations to support extreme multi-scale scene rendering, from city-scale context to high-detail objects.

Dataset

AgiBot-World: The Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
Introducing AgiBot World, a large-scale platform comprising over 1 million trajectories across 217 tasks in five deployment scenarios. Accelerated by a standardized collection pipeline with human-in-the-loop verification, AgiBot World guarantees high-quality and diverse data distribution.

Manipulation



OpenDV
The largest driving video dataset to date, containing more than 1700 hours of real-world driving videos.

Autonomous Driving
World Model